
O termo data lake foi popularizado em 2010 por James Dixon, então CTO da Pentaho. Na ocasião, ele usou a metáfora de um lado para explicar como esse tipo de repositório difere de sistemas mais rígidos, como o data Warehouse.
Em vez de armazenar dados já tratados e padronizados, o data lake recebe a informação em seu formato bruto, seja ela estruturada (planilhas, tabelas), semiestruturadas (JSON, XML) ou não estruturada (imagens, vídeos, áudios, logs de aplicativos).
Por que essa ideia foi revolucionária? Porque as empresas estavam presas a silos de dados. Cada área mantinha seu próprio banco, com pouca integração e muita redundância.
Isso dificultava análises estratégicas e atrasava a tomada de decisão. O data lake surge como uma solução centralizada, onde tudo pode ser armazenado de forma acessível para diferentes usos.
Data lake x banco de dados tradicional
É comum confundir um data lake com um banco de dados relacional (como MySQL, PostgreSQL ou Oracle). Mas as diferenças são marcantes:
Banco de dados tradicional
- Armazena dados estruturados em tabelas.
- É ótimo para operações transacionais (cadastros, vendas, registros).
- Exige que o dado esteja no formato correto antes do armazenamento.
Data lake
- Armazena qualquer tipo de dado (estruturado, semiestruturado e não estruturado).
- É voltado para análises avançadas, Big Data e machine learning.
- Permite guardar primeiro e estruturar depois (abordagem scherma-on-read).
Essa flexibilidade faz com que o data lake seja cada vez mais adotado em projetos de transformação digital e inteligência artificial.
Afinal, como treinar um modelo de machine learning se parte dos dados da empresa está presa em planilhas, outra parte em sistemas isolados e o restante em arquivos dispersos?
Nos próximos tópicos, você vai descobrir as diferenças entre data lake, data warehouse e Big Data, além de entender como aplicar esse conceito na prática com exemplos de AWS, Google Cloud e Azure.
Continue a leitura para saber qual modelo faz mais sentido para a sua empresa.
Data lake vs. data warehouse vs. data lakehouse
Quem está começando a explorar o universo de dados inevitavelmente se depara com esses três termos. Embora sejam frequentemente confundidos, data lake, data Warehouse e data lakehouse têm propósitos diferentes e se complementam dentro da estratégia de dados de uma empresa.
Esquema de armazenamento: schema on read vs. Schema on write
- Data lake (schema on read): os dados são armazenados em formato bruto e só são estruturados quando lidos para análise. Isso dá mais liberdade para diferentes usos no futuro.
- Data Warehouse (schema on write): os dados precisam ser tratados e organizados antes do armazenamento. Isso garante consistência e qualidade, mas exige mais tempo de preparação.
Em outras palavras: no data lake você armazena primeiro e organiza depois; no data warehouse você organiza antes de armazenar.
Tipos de dados aceitos
- Data lake: aceita qualquer tipo de dado — estruturado (planilhas, tabelas), semiestruturado (JSON, XML) e não estruturado (áudio, vídeo, imagens, logs).
- Data warehouse: trabalha apenas com dados estruturados, já prontos para relatórios e consultas rápidas.
Finalidade e usuários
- Data lake: voltado para cientistas de dados, engenheiros e equipes de inovação, que precisam explorar informações brutas e treinar modelos de machine learning.
- Data Warehouse: usado principalmente por analistas de BI, gestores e executivos, interessados em relatórios confiáveis, dashboars e análises históricas.
Custo e escabilidade
- Data lakes costumam ser mais baratos e escaláveis, especialmente quando implementados em nuvem (ex.: Wevy Cloud, Azure Data Lake, Google Cloud Storage).
- Data warehouses exigem mais processamento e preparo dos dados, o que os torna mais caros e menos flexíveis para grandes volumes.
Governo e segurança
- Data Warehouse: possui governança e segurança robustas, garantindo confiabilidade para relatórios financeiros, auditorias e conformidade regulatória.
- Data lake: sem políticas adequadas, corre o risco de virar um “data swamp” (pântano de dados — um repositório desorganizado e de difícil aproveitamento. Por isso, implementar políticas de catalogação, metadados e acesso é fundamental.
Lakehouse: a fusão dos dois mundos
Nos últimos anos, surgiu um novo conceito: o data lakehouse. Ele combina a flexibilidade do data lake com a governança e performance do data Warehouse.
Assim, enquanto o data lake e o data warehouse podem coexistir, o lakehouse surge como tendência para integrar ambos em uma arquitetura mais ágil e escalável.
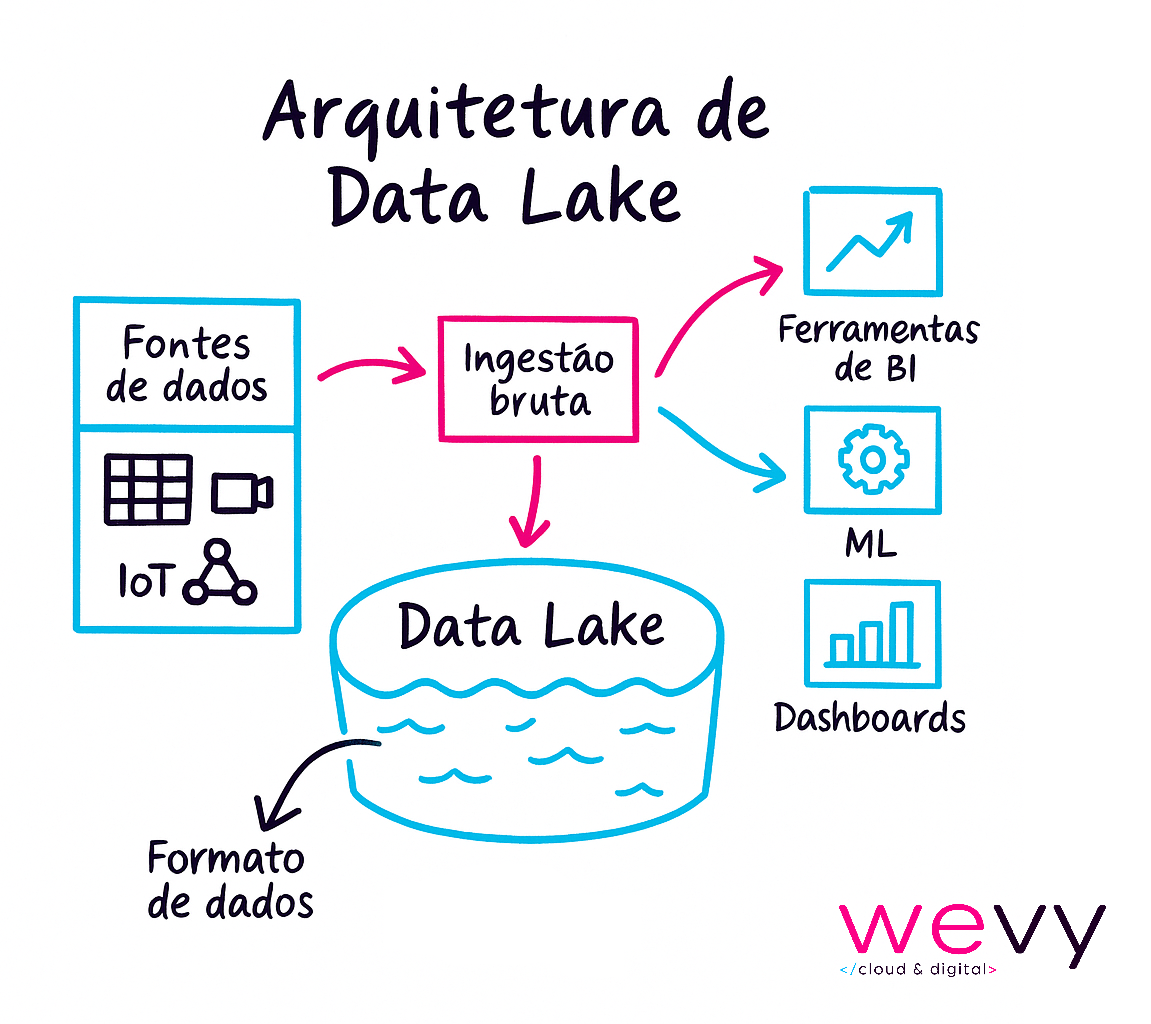
Como funciona um data lake
Para entender como um Data Lake opera na prática, é importante visualizar sua arquitetura em camadas.
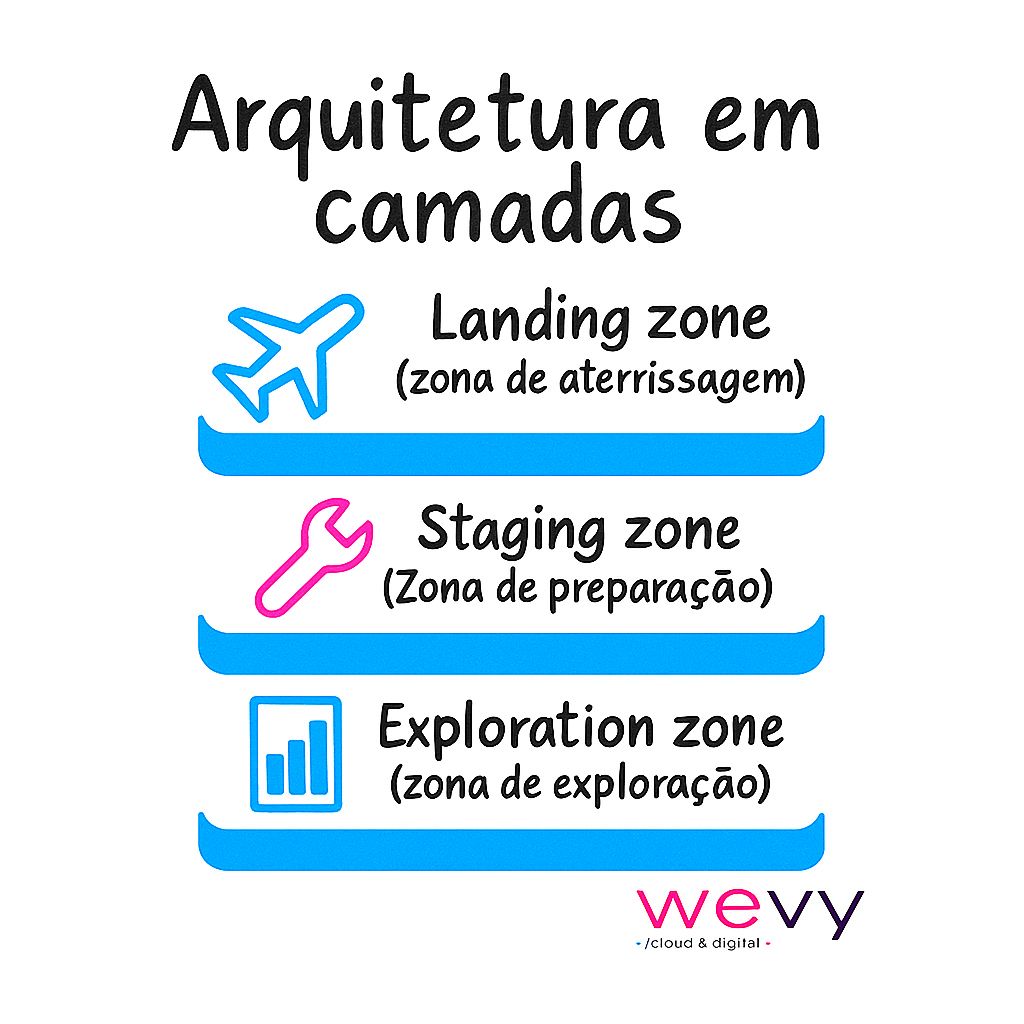
1. Landing zone (zona de aterrissagem):
Aonde os dados chegam em seu formato original, vindos de diferentes fontes — sistemas de ERP, CRM, sensores IoT, redes sociais, aplicativos, planilhas etc. Não há transformação nessa etapa, apenas ingestão.
2. Staging zone (Zona de preparação):
Área intermediária, onde os dados começam a ser validados, limpos e, em alguns casos, convertidos para formato mais adequados. É aqui que se reduz redundância e ruído antes de análises mais profundas.
3. Exploration zone (zona de exploração):
Espaço em que cientistas e analistas de dados exploram informações, criam modelos preditivos, relatórios ou alimentam aplicações de inteligência artificial.
Essa arquitetura garante que os dados possam ser armazenados de forma massiva, organizada e acessível a diferentes perfis de usuários.
Etapas principais do funcionamento de um Data Lake
Um data lake funciona a partir de um fluxo contínuo que pode ser dividido em cinco etapas:
- Ingestão de dados: coleta dados de múltiplas fontes em tempo real ou em batch.
- Armazenamento: guarda tudo em formato bruto, sem necessidade de padronização;
- Catalogação: indexa e organiza os metadados, facilitando a busca e o uso posterior;
- Processamento e análise: aplica transformações, agregações e análises usando frameworks como Apache Spark, Hadoop ou Presto.
- Consumo: usuários e aplicações acessam os dados para gerar insights via ferramentas de BI, dashboards ou modelos de machine learning.
Schema on read vs. Schema on write
Um dos grandes diferenciais do data lake está em como os dados são tratados:
- Schema on read (data lake): os dados permanecem brutos até o momento da leitura. Isso significa que o formato é aplicado apenas quando alguém precisa consultar ou analisar.
- Schema on write (data warehouse): os dados precisam ser transformados e organizados antes de serem gravados.
Essa diferença dá ao data lake uma flexibilidade enorme, já que permite armazenar informações primeiro e decidir a estrutura depois.
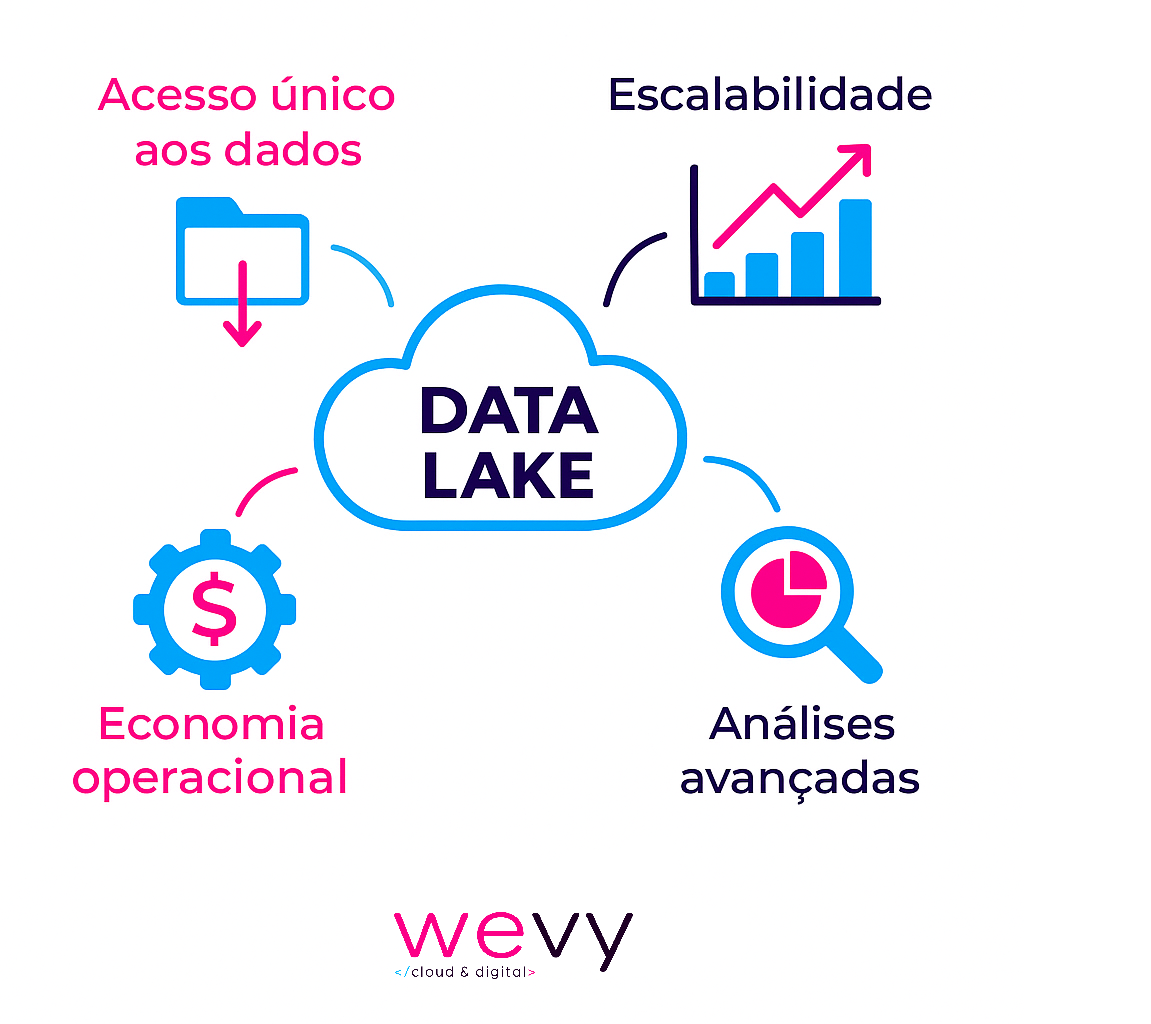
Benefícios de adotar um data lake
Implementar um data lake não é apenas uma tendência tecnológica — é uma estratégia para empresas que querem competir em um mercado cada vez mais orientado por dados.
Entre os principais benefícios apontados por especialistas e grandes provedores de nuvem, destacam-se:
Flexibilidade para qualquer tipo de dados
Um dos maiores diferenciais do data lake é a capacidade de armazenar dados estruturados, semiestruturados e não estruturados no mesmo ambiente.
Isso significa que relatórios financeiros, registros de sensores IoT, interações em redes sociais e até vídeos podem coexistir no mesmo repositório.
Essa flexibilidade abre espaço para análises exploratórias, em que cientistas de dados podem descobrir padrões ocultos sem a limitação de formatos rígidos.
Escalabilidade e custo reduzido
Data lakes em nuvem, oferecem armazenamento elástico. Ou seja, sua empresa paga apenas pelo que usa e pode expandir facilmente conforme a quantidade de dados cresce.
Além disso, os custos de armazenamento em data lake costumam ser significativamente menores que os bancos tradicionais ou data warehouses.
Suporte a Big Data e Machine Learning
Como o data lake, é possível alimentar frameworks de Big Data e modelos de IA/ML diretamente com dados brutos. Isso acelera o desenvolvimento de soluções preditivas, como:
- Previsão de demanda no varejo.
- Recomendação personalizada em e-commerces.
- Diagnóstico assistido por IA na área da saúde.
- Manutenção preditiva em indústrias.
Insights de negócio e inovação
Ao centralizar dados de múltiplas fontes, o data lake se torna um motor de inteligência para a organização. Ele possibilita:
- Melhorar a experiência do cliente: personalizando ofertas e jornadas digitais.
- Otimizar operações: ajustando estoques, rotas logísticas e custos operacionais.
- Apoiar pesquisas e inovação: explorando dados científicos, genômicos ou de sensores para acelerar descobertas.
Centralização e integração de dados
Em vez de cada área manter seus próprios bancos isolados, o data lake cria um repositório único que integra dados de:
- Sistemas internos: ERPs, CRMs, softwares de RH.
- IoT: máquinas conectadas, wearables, sensores industriais.
- Redes sociais e web: menções de marca, comportamento digital.
- Streaming em tempo real: logs de aplicativos, transações financeiras, dispositivos móveis.
Esse ecossistema integrado garante uma visão 360° do negócio, algo impossível quando as informações estão espalhadas em silos.
Desafios e riscos (data swamp)
Embora o data lake ofereça inúmeros benefícios, ele também traz riscos importantes quando não é implementado com uma estratégia clara.
É por isso que especialistas alertam para o perigo da chamada “data swamp” — um lago que se transforma em um pântano de dados inutilizáveis.
Governança insuficiente
Sem catálogo, classificação e controle de acesso, o data lake rapidamente perde sua utilidade. Imagine milhares de arquivos sendo depositados sem qualquer organização: em pouco tempo, encontrar um dado confiável se torna quase impossível.
É como ter uma biblioteca sem prateleiras nem índice: os livros estão lá, mas ninguém sabe onde buscar.
Qualidade dos dados
Como o data lake armazena informações em formato bruto, é comum encontrar duplicidades, inconsistências e dados corrompidos.
Isso pode comprometer análises e modelos de IA, já que resultados incorretos são inevitáveis quando a base de origem está contaminada.
Exemplo: um varejista que importa dados de vendas de diferentes sistemas sem padronização pode acabar com produtos cadastrados duas vezes ou valores divergentes, impactando relatórios estratégicos.
Complexidade de integração e competências necessárias
Para transformar o data lake em valor real, é preciso contar com profissionais especializados em ciência de dados, engenharia de dados e arquitetura de nuvem.
A simples existência do repositório não garante insights: sem pessoas capacitadas e ferramentas adequadas, os dados permanecem brutos e inexplorados.
Custos ocultos
Embora o armazenamento em nuvem seja escalável e barato no início, a falta de gestão pode gerar custos ocultos.
Armazenar dados indefinidamente ou processá-los sem critério pode aumentar a fatura de forma inesperada.
Em resumo: sem governança, qualidade, competências e estratégia, o data lake pode deixar de ser um ativo valioso e virar um passivo custoso.
Por isso, a chave do sucesso está em planejar, catalogar e controlar o uso desde o início.
Casos de uso e exemplos práticos
Varejo e marketing
No varejo, combinar diferentes fontes de dados é essencial para entender o comportamento do consumidor. Um data lake permite integrar:
- Histórico de vendas de lojas físicas.
- Cliques e navegação em sites e e-commerces.
- Condições climáticas e notícias de mercado.
Com essa base, é possível prever demanda de produtos e personalizar ofertas em tempo real.
Um cliente que pesquisou tênis em um e-commerce, por exemplo, pode receber recomendações de modelos específicos com base em clima, tendências regionais e estoque disponível.
Finanças e seguros
Instituições financeiras lidam com grandes volumes de transações e precisam de análises rápidas para evitar riscos. O data lake viabiliza:
- Detecção de fraudes em tempo real cruzando dados de compras, dispositivos e geolocalização.
- Análise de risco de carteira, combinando histórico de clientes com variáveis econômicas.
- Previsões de crédito mais precisas, integrando dados de comportamento digital e histórico bancário.
Manufatura e IoT
Na indústria, sensores IoT instalados em máquinas geram milhares de dados por segundo. Em um data lake, essas informações podem ser exploradas para:
- Implementar manutenção preditiva, reduzindo falhas inesperadas.
- Monitorar logs de operação para identificar gargalos.
- Otimizar cadeias de produção com base em dados históricos e em tempo real.
Saúde e pesquisa científica
O setor da saúde é um dos que mais se beneficia do data lake. Ele possibilita:
- Análises genômicas para personalizar tratamentos.
- Integração de experimentos clínicos em escala global.
- Apoio a pesquisas científicas que exigem cruzamento de grandes volumes de dados biomédicos.
Durante a pandemia, data lakes ajudaram laboratórios a processar dados de testes, prontuários e pesquisas simultaneamente, acelerando a busca por vacinas e tratamentos.
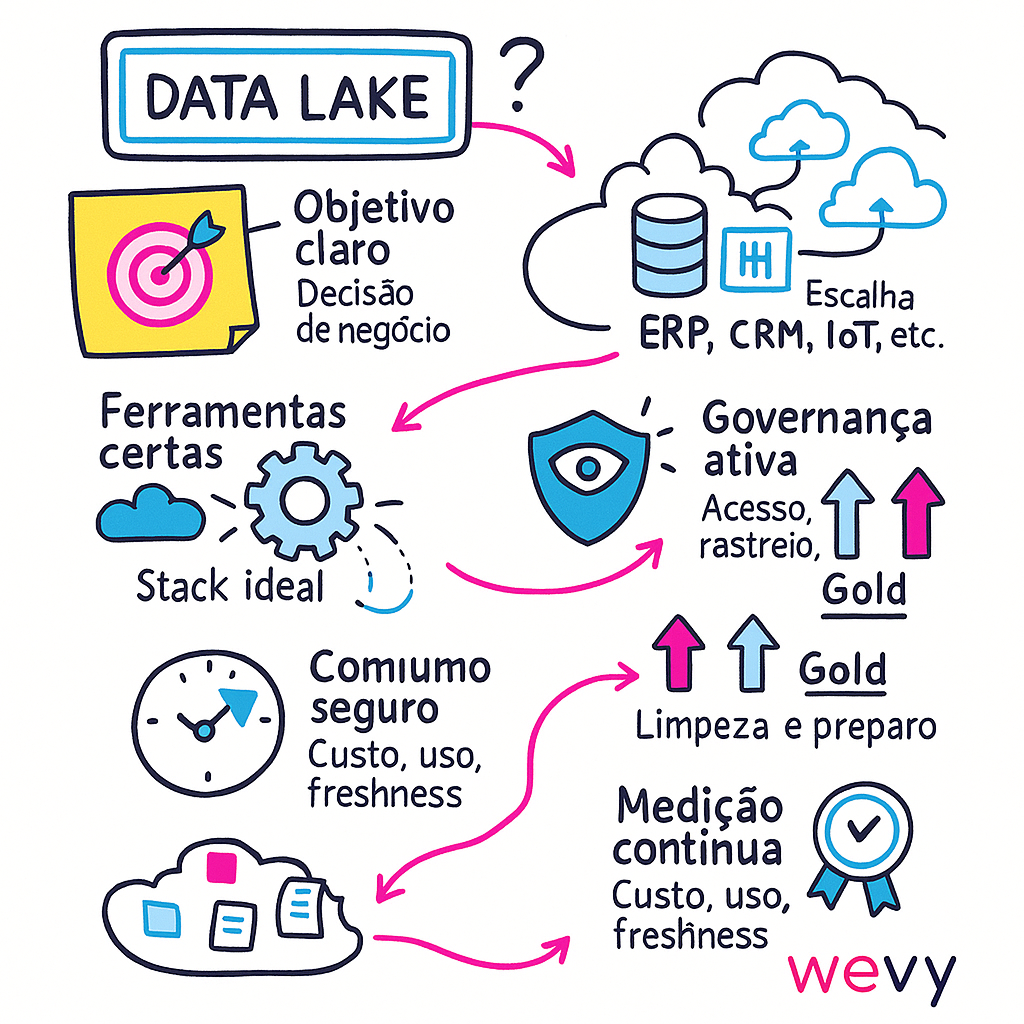
Como criar um data lake
Criar um data lake não é um projeto de ferramenta, e sim de estratégia. O caminho mais seguro é avançar por etapas curtas, com governança. Por onde começar?
- Definição de objetivos e requisitos de negócio
Antes da tecnologia, alinhe porque o data lake existe. Quais decisões ele vai acelerar? Quais perguntas precisa responder nos próximos 90 dias?
Defina casos de uso âncora (ex.: previsão de demanda, redução de churn) e KPIs (tempo para insight, custo por consulta, precisão de modelos). Sem foco, o lago vira depósito.
- Levantamento de fontes de dados
Mapeie todas as origens: ERPs/CRMs, planilhas, IoT, redes sociais, logs de apps, APIs e bases externas. Para cada fonte, registre formato (CSV, JSON, Parquet), volume/frequência, latência (batch vs. streaming) e sensibilidade (PII/LGPD).
Esse inventário sustenta a priorização de ingestão e as regras de segurança.
- Escolha da arquitetura (onpremise, nuvem, híbrida ou multicloud)
Decida onde o lago vive considerando escala, compliance e TCO.
Nuvem: elasticidade e custo variável—excelente para escalar rápido.
On-premise: quando baixa latência local ou requisitos regulatórios exigem.
Híbrida/multicloud: evita lock-in e aproxima dados de sistemas críticos.
- Ferramentas e serviços
Monte o “kit” por domínio:
– Armazenamento: Amazon S3, Google Cloud Storage, Azure Data Lake Storage.
– Ingestão/ETL-ELT: AWS Glue/Lake Formation, Cloud Data Fusion, Azure Data Factory; streaming com Kafka, Pub/Sub, Event Hubs.
– Catálogo/linha de dados: Glue Data Catalog, Data Catalog (GCP), Purview (Azure).
– Processamento/consulta: Spark (EMR/Dataproc/Databricks), Hadoop, Presto/Trino, Athena, Synapse Serverless, BigQuery (tabelas externas).
– Formato e tabelas abertas: Delta Lake, Apache Hudi ou Iceberg para ACID, time-travel e evolução de schema.
Escolha pensando no caso de uso e nos skills do time.
- Governança e segurança desde o início
Não basta apenas armazenar os dados — é essencial protegê-los. Garanta controle de acesso baseado em papéis, criptografia em repouso e em trânsito, além de catálogo de metadados para rastreabilidade.
Políticas de classificação e auditoria contínua ajudam a manter o lago confiável e em conformidade (ex.: LGPD).
- Implementação de governança e segurança
Na prática, coloque as políticas para rodar:
– Classificação de dados (público, confidencial, restrito).
– Controle de acesso granular com IAM ou RBAC.
– Mascaramento e tokenização de informações sensíveis.
– Monitoramento ativo (logs, alertas de anomalias, trilhas de auditoria).
- Processos de limpeza e transformação
Crie pipelines de deduplicação, validação, enriquecimento e normalização. Isso prepara os dados para análises sem comprometer a qualidade.
Uma boa prática é adotar a arquitetura em camadas: Bronze (bruto) → Silver (limpo) → Gold (pronto para consumo).
- Consumo e exploração
Disponibilize os dados de forma acessível e segura:
– Ferramentas de BI (Power BI, Tableau, Looker).
– Notebooks interativos para cientistas de dados (Databricks, Jupyter, Zeppelin).
– Plataformas de ML (SageMaker, Vertex AI, Azure ML).
Assim, cada perfil da empresa encontra os dados no formato ideal para gerar valor.
- Monitoramento e evolução
Implemente métricas para acompanhar o sucesso: custo por TB, tempo de processamento, taxa de falhas, freshness dos dados, adoção por áreas de negócio.
Revise regularmente a arquitetura e ajuste de acordo com os novos casos de uso, aplicando práticas de FinOps para manter custos sob controle.
Tipos de data lake e implementação
Ao pensar em adotar um data lake, um dos pontos mais estratégicos é definir o tipo de implementação que melhor atende às necessidades da empresa.
Cada modalidade traz vantagens e limitações em termos de custo, elasticidade, compliance e integração com os sistemas já existentes.
- Onpremise: hospedado dentro do próprio data center da empresa, oferece total controle sobre infraestrutura, segurança e governança. Por outro lado, exige alto investimento inicial em hardware e manutenção, além de apresentar menor elasticidade diante de picos de demanda.
- Nuvem: modelo mais popular atualmente, garante elasticidade, escalabilidade sob demanda e custos variáveis (pay as you go). A segurança é compartilhada com o provedor, que assume grande parte da responsabilidade de infraestrutura.
- Híbrido: ideal para organizações que precisam manter dados sensíveis em ambiente local (por questões de compliance, como LGPD ou regulamentos de setor) mas desejam aproveitar os benefícios da nuvem para processar grandes volumes e análises mais intensivas.
- Multicloud: cada vez mais adotado por empresas globais, esse modelo combina provedores diferentes (AWS, Azure, GCP) para evitar vendor lock-in, otimizar custos e integrar recursos específicos de cada plataforma.
A complexidade de gestão é maior, mas pode trazer flexibilidade e resiliência.
A escolha do tipo de data lake depende de fatores como:
- Volume e crescimento dos dados (se há picos de ingestão ou carga constante).
- Exigências de compliance e regulamentação (ex.: dados que não podem sair do país).
- Integração com sistemas existentes (ERPs, CRMs, IoT, APIs).
- Capacidade da equipe de TI e orçamento disponível.
Perguntas frequentes (FAQ)
- “O que é um data lake?”
Um data lake é um repositório central capaz de armazenar grandes volumes de dados em diferentes formatos — estruturados, semiestruturados e não estruturados — de forma bruta, permitindo análises avançadas e flexíveis no futuro.
- “Qual a diferença entre data lake e data warehouse?”
O data lake armazena dados brutos e variados, prontos para exploração, enquanto o data warehouse guarda dados já tratados e organizados para relatórios e análises estruturadas. Em resumo: lake é flexibilidade; warehouse é precisão e governança.
- “O que é Big Data e qual a relação com data lake?”
Big Data refere-se ao grande volume, variedade e velocidade de geração de dados. O data lake surge justamente como solução para lidar com esse cenário, oferecendo escalabilidade e suporte a análises complexas, como inteligência artificial e machine learning.
- “Como criar um data lake?”
O processo envolve definir objetivos de negócio, levantar fontes de dados, escolher a arquitetura (on premise, nuvem, híbrida ou multi cloud), adotar ferramentas de ingestão, armazenamento e processamento, aplicar governança e segurança, e integrar com ferramentas analíticas.
- “Data lake serve para pequenas empresas?”
Sim. Embora o conceito tenha nascido em grandes corporações, hoje existem soluções em nuvem acessíveis que permitem a pequenas empresas centralizar dados, gerar insights e escalar conforme o crescimento, sem altos custos iniciais.
- “O que é data lakehouse?”
É uma evolução do modelo de data lake que une sua flexibilidade com a governança e confiabilidade do data warehouse. Com isso, a arquitetura se torna mais simples, evita redundâncias e reduz custos.
Conclusão: transforme seus dados em inteligência estratégica
Adotar um data lake é um passo essencial para empresas que desejam explorar o potencial do Big Data, Inteligência Artificial e análises avançadas. Mas, para que essa jornada seja bem-sucedida, é fundamental contar com uma infraestrutura confiável, escalável e com governança desde o início.
A Wevy, primeira multinacional brasileira de cloud computing, é especialista em Dados & IA e pode ser sua parceira estratégica para centralizar, organizar e explorar seus dados com segurança e alta performance.
Fale com um especialista da Wevy e descubra como levar sua empresa para a próxima fase da transformação digital.